Kettle(PDI )连接MySQL8数据库
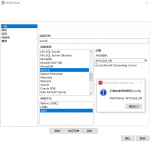
1、将Kettle连接MySQL的驱动包mysql-connector-java-8.0.27.jar放入lib文件目录。例如C:\java\data-integration\lib。
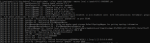
2、修改C:\java\data-integration\simple-jndi目录下的jdbc.properties配置文件。加上如下内容(world为数据库名称,MYSQL8_DB为JNDI名称):
MYSQL8_DB/type=javax.sql.DataSource
MYSQL8_DB/dri