1、Hadoop。
tar -zxvf hadoop-2.9.1.tar.gz
ln -s hadoop-2.9.1 hadoop
cd home/hadoop/app/hadoop/etc/hadoop
2、修改配置文件。
(1)hadoop-env.sh。主要设置 export JAVA_HOME=/home/hadoop/app/jdk
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
##
## THIS FILE ACTS AS THE MASTER FILE FOR ALL HADOOP PROJECTS.
## SETTINGS HERE WILL BE READ BY ALL HADOOP COMMANDS. THEREFORE,
## ONE CAN USE THIS FILE TO SET YARN, HDFS, AND MAPREDUCE
## CONFIGURATION OPTIONS INSTEAD OF xxx-env.sh.
##
## Precedence rules:
##
## {yarn-env.sh|hdfs-env.sh} > hadoop-env.sh > hard-coded defaults
##
## {YARN_xyz|HDFS_xyz} > HADOOP_xyz > hard-coded defaults
##
# Many of the options here are built from the perspective that users
# may want to provide OVERWRITING values on the command line.
# For example:
#
# JAVA_HOME=/usr/java/testing hdfs dfs -ls
#
# Therefore, the vast majority (BUT NOT ALL!) of these defaults
# are configured for substitution and not append. If append
# is preferable, modify this file accordingly.
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/home/hadoop/app/jdk
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/home/hadoop/app/hadoop
# Location of Hadoop's configuration information. i.e., where this
# file is living. If this is not defined, Hadoop will attempt to
# locate it based upon its execution path.
#
# NOTE: It is recommend that this variable not be set here but in
# /etc/profile.d or equivalent. Some options (such as
# --config) may react strangely otherwise.
#
# export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=
# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
# Enable extra debugging of Hadoop's JAAS binding, used to set up
# Kerberos security.
# export HADOOP_JAAS_DEBUG=true
# Extra Java runtime options for all Hadoop commands. We don't support
# IPv6 yet/still, so by default the preference is set to IPv4.
# export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true"
# For Kerberos debugging, an extended option set logs more information
# export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true -Dsun.security.krb5.debug=true -Dsun.security.spnego.debug"
# Some parts of the shell code may do special things dependent upon
# the operating system. We have to set this here. See the next
# section as to why....
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
# Extra Java runtime options for some Hadoop commands
# and clients (i.e., hdfs dfs -blah). These get appended to HADOOP_OPTS for
# such commands. In most cases, # this should be left empty and
# let users supply it on the command line.
# export HADOOP_CLIENT_OPTS=""
#
# A note about classpaths.
#
# By default, Apache Hadoop overrides Java's CLASSPATH
# environment variable. It is configured such
# that it starts out blank with new entries added after passing
# a series of checks (file/dir exists, not already listed aka
# de-deduplication). During de-deduplication, wildcards and/or
# directories are *NOT* expanded to keep it simple. Therefore,
# if the computed classpath has two specific mentions of
# awesome-methods-1.0.jar, only the first one added will be seen.
# If two directories are in the classpath that both contain
# awesome-methods-1.0.jar, then Java will pick up both versions.
# An additional, custom CLASSPATH. Site-wide configs should be
# handled via the shellprofile functionality, utilizing the
# hadoop_add_classpath function for greater control and much
# harder for apps/end-users to accidentally override.
# Similarly, end users should utilize ${HOME}/.hadooprc .
# This variable should ideally only be used as a short-cut,
# interactive way for temporary additions on the command line.
# export HADOOP_CLASSPATH="/some/cool/path/on/your/machine"
# Should HADOOP_CLASSPATH be first in the official CLASSPATH?
# export HADOOP_USER_CLASSPATH_FIRST="yes"
# If HADOOP_USE_CLIENT_CLASSLOADER is set, the classpath along
# with the main jar are handled by a separate isolated
# client classloader when 'hadoop jar', 'yarn jar', or 'mapred job'
# is utilized. If it is set, HADOOP_CLASSPATH and
# HADOOP_USER_CLASSPATH_FIRST are ignored.
# export HADOOP_USE_CLIENT_CLASSLOADER=true
# HADOOP_CLIENT_CLASSLOADER_SYSTEM_CLASSES overrides the default definition of
# system classes for the client classloader when HADOOP_USE_CLIENT_CLASSLOADER
# is enabled. Names ending in '.' (period) are treated as package names, and
# names starting with a '-' are treated as negative matches. For example,
# export HADOOP_CLIENT_CLASSLOADER_SYSTEM_CLASSES="-org.apache.hadoop.UserClass,java.,javax.,org.apache.hadoop."
# Enable optional, bundled Hadoop features
# This is a comma delimited list. It may NOT be overridden via .hadooprc
# Entries may be added/removed as needed.
# export HADOOP_OPTIONAL_TOOLS="hadoop-aliyun,hadoop-openstack,hadoop-azure,hadoop-azure-datalake,hadoop-aws,hadoop-kafka"
###
# Options for remote shell connectivity
###
# There are some optional components of hadoop that allow for
# command and control of remote hosts. For example,
# start-dfs.sh will attempt to bring up all NNs, DNS, etc.
# Options to pass to SSH when one of the "log into a host and
# start/stop daemons" scripts is executed
# export HADOOP_SSH_OPTS="-o BatchMode=yes -o StrictHostKeyChecking=no -o ConnectTimeout=10s"
# The built-in ssh handler will limit itself to 10 simultaneous connections.
# For pdsh users, this sets the fanout size ( -f )
# Change this to increase/decrease as necessary.
# export HADOOP_SSH_PARALLEL=10
# Filename which contains all of the hosts for any remote execution
# helper scripts # such as workers.sh, start-dfs.sh, etc.
# export HADOOP_WORKERS="${HADOOP_CONF_DIR}/workers"
###
# Options for all daemons
###
#
#
# Many options may also be specified as Java properties. It is
# very common, and in many cases, desirable, to hard-set these
# in daemon _OPTS variables. Where applicable, the appropriate
# Java property is also identified. Note that many are re-used
# or set differently in certain contexts (e.g., secure vs
# non-secure)
#
# Where (primarily) daemon log files are stored.
# ${HADOOP_HOME}/logs by default.
# Java property: hadoop.log.dir
# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
# A string representing this instance of hadoop. $USER by default.
# This is used in writing log and pid files, so keep that in mind!
# Java property: hadoop.id.str
# export HADOOP_IDENT_STRING=$USER
# How many seconds to pause after stopping a daemon
# export HADOOP_STOP_TIMEOUT=5
# Where pid files are stored. /tmp by default.
# export HADOOP_PID_DIR=/tmp
# Default log4j setting for interactive commands
# Java property: hadoop.root.logger
# export HADOOP_ROOT_LOGGER=INFO,console
# Default log4j setting for daemons spawned explicitly by
# --daemon option of hadoop, hdfs, mapred and yarn command.
# Java property: hadoop.root.logger
# export HADOOP_DAEMON_ROOT_LOGGER=INFO,RFA
# Default log level and output location for security-related messages.
# You will almost certainly want to change this on a per-daemon basis via
# the Java property (i.e., -Dhadoop.security.logger=foo). (Note that the
# defaults for the NN and 2NN override this by default.)
# Java property: hadoop.security.logger
# export HADOOP_SECURITY_LOGGER=INFO,NullAppender
# Default process priority level
# Note that sub-processes will also run at this level!
# export HADOOP_NICENESS=0
# Default name for the service level authorization file
# Java property: hadoop.policy.file
# export HADOOP_POLICYFILE="hadoop-policy.xml"
#
# NOTE: this is not used by default! <-----
# You can define variables right here and then re-use them later on.
# For example, it is common to use the same garbage collection settings
# for all the daemons. So one could define:
#
# export HADOOP_GC_SETTINGS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps"
#
# .. and then use it as per the b option under the namenode.
###
# Secure/privileged execution
###
#
# Out of the box, Hadoop uses jsvc from Apache Commons to launch daemons
# on privileged ports. This functionality can be replaced by providing
# custom functions. See hadoop-functions.sh for more information.
#
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
# export JSVC_HOME=/usr/bin
#
# This directory contains pids for secure and privileged processes.
#export HADOOP_SECURE_PID_DIR=${HADOOP_PID_DIR}
#
# This directory contains the logs for secure and privileged processes.
# Java property: hadoop.log.dir
# export HADOOP_SECURE_LOG=${HADOOP_LOG_DIR}
#
# When running a secure daemon, the default value of HADOOP_IDENT_STRING
# ends up being a bit bogus. Therefore, by default, the code will
# replace HADOOP_IDENT_STRING with HADOOP_xx_SECURE_USER. If one wants
# to keep HADOOP_IDENT_STRING untouched, then uncomment this line.
# export HADOOP_SECURE_IDENT_PRESERVE="true"
###
# NameNode specific parameters
###
# Default log level and output location for file system related change
# messages. For non-namenode daemons, the Java property must be set in
# the appropriate _OPTS if one wants something other than INFO,NullAppender
# Java property: hdfs.audit.logger
# export HDFS_AUDIT_LOGGER=INFO,NullAppender
# Specify the JVM options to be used when starting the NameNode.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# a) Set JMX options
# export HDFS_NAMENODE_OPTS="-Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=1026"
#
# b) Set garbage collection logs
# export HDFS_NAMENODE_OPTS="${HADOOP_GC_SETTINGS} -Xloggc:${HADOOP_LOG_DIR}/gc-rm.log-$(date +'%Y%m%d%H%M')"
#
# c) ... or set them directly
# export HDFS_NAMENODE_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:${HADOOP_LOG_DIR}/gc-rm.log-$(date +'%Y%m%d%H%M')"
# this is the default:
# export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS"
###
# SecondaryNameNode specific parameters
###
# Specify the JVM options to be used when starting the SecondaryNameNode.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# This is the default:
# export HDFS_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS"
###
# DataNode specific parameters
###
# Specify the JVM options to be used when starting the DataNode.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# This is the default:
# export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS"
# On secure datanodes, user to run the datanode as after dropping privileges.
# This **MUST** be uncommented to enable secure HDFS if using privileged ports
# to provide authentication of data transfer protocol. This **MUST NOT** be
# defined if SASL is configured for authentication of data transfer protocol
# using non-privileged ports.
# This will replace the hadoop.id.str Java property in secure mode.
# export HDFS_DATANODE_SECURE_USER=hdfs
# Supplemental options for secure datanodes
# By default, Hadoop uses jsvc which needs to know to launch a
# server jvm.
# export HDFS_DATANODE_SECURE_EXTRA_OPTS="-jvm server"
###
# NFS3 Gateway specific parameters
###
# Specify the JVM options to be used when starting the NFS3 Gateway.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_NFS3_OPTS=""
# Specify the JVM options to be used when starting the Hadoop portmapper.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_PORTMAP_OPTS="-Xmx512m"
# Supplemental options for priviliged gateways
# By default, Hadoop uses jsvc which needs to know to launch a
# server jvm.
# export HDFS_NFS3_SECURE_EXTRA_OPTS="-jvm server"
# On privileged gateways, user to run the gateway as after dropping privileges
# This will replace the hadoop.id.str Java property in secure mode.
# export HDFS_NFS3_SECURE_USER=nfsserver
###
# ZKFailoverController specific parameters
###
# Specify the JVM options to be used when starting the ZKFailoverController.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_ZKFC_OPTS=""
###
# QuorumJournalNode specific parameters
###
# Specify the JVM options to be used when starting the QuorumJournalNode.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_JOURNALNODE_OPTS=""
###
# HDFS Balancer specific parameters
###
# Specify the JVM options to be used when starting the HDFS Balancer.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_BALANCER_OPTS=""
###
# HDFS Mover specific parameters
###
# Specify the JVM options to be used when starting the HDFS Mover.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_MOVER_OPTS=""
###
# Router-based HDFS Federation specific parameters
# Specify the JVM options to be used when starting the RBF Routers.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_DFSROUTER_OPTS=""
###
# HDFS StorageContainerManager specific parameters
###
# Specify the JVM options to be used when starting the HDFS Storage Container Manager.
# These options will be appended to the options specified as HADOOP_OPTS
# and therefore may override any similar flags set in HADOOP_OPTS
#
# export HDFS_STORAGECONTAINERMANAGER_OPTS=""
###
# Advanced Users Only!
###
#
# When building Hadoop, one can add the class paths to the commands
# via this special env var:
# export HADOOP_ENABLE_BUILD_PATHS="true"
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
# export HDFS_NAMENODE_USER=hdfs
(2)core-site.xml 主要配置Hadoop的共有属性。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--默认的HDFS路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
<!--hadoop的临时目录,如果需要配置多个目录,需要逗号隔开-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--配置Zookeeper 管理HDFS-->
</configuration>
(3)hdfs-site.xml 要配置和HDFS相关的属性。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--数据块副本数为3-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--权限默认配置为false-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,mycluster是对外提供的统一入口-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 指定 nameService 是 mycluster时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--启动故障自动恢复-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<!--指定NameNode的元数据在JournalNode上的存放位置-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--指定 mycluster 出故障时,哪个实现类负责执行故障切换-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<!-- 配置隔离机制,shell通过ssh连接active namenode节点,杀掉进程-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 为了实现SSH登录杀掉进程,还需要配置免密码登录的SSH密匙信息 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
(4)slaves 主要配置DataNode节点所在的主机名。
hadoop01 hadoop02 hadoop03
(5)向hadoop02、hadoop03节点复制Hadoop安装目录。
scp -r hadoop-2.9.1 hadoop@hadoop02:/home/hadoop/app/
scp -r hadoop-2.9.1 hadoop@hadoop03:/home/hadoop/app/
3、启动集群
(1)启动Zookeeper集群服务。节点hadoop01、hadoop02、hadoop03分别执行。
/home/hadoop/app/zookeeper/bin/zkServer.sh start
(2)启动JournalNode集群。节点hadoop01、hadoop02、hadoop03分别执行。
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode
(3)格式化主节点NameNode。
bin/hdfs namenode -format
bin/hdfs zkfc -formatZK
bin/hdfs namenode
(4)备用NameNode同步主节点的元数据
bin/hdfs namenode -bootstrapStandby
(5)关闭JournalNode集群。节点hadoop01(ctrl + c 结束NameNode进程)、hadoop02、hadoop03分别执行。
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode
(6)一键启动HDFS集群。第一次安装HDFS需要对NameNode进行格式化。HDFS安装成功以后,使用一键启动脚本start-dfs.sh即可启动HDFS集群所有进程。
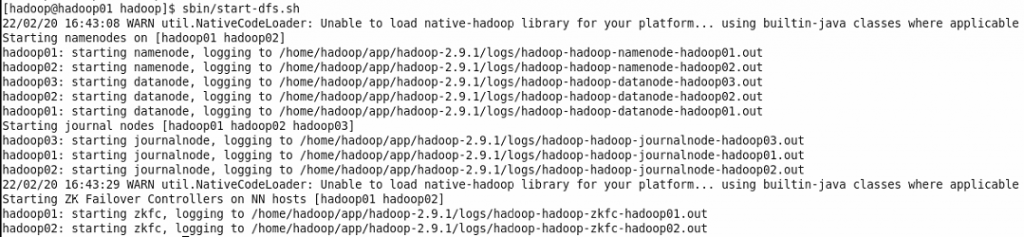
4、验证HDFS是否启动成功。如果无法启动,则需要检查home/hadoop/data目录下的journaldata、tmp目录的读写权限,home/hadoop/app/hadoop-2.9.1目录下的logs目录的读写权限。
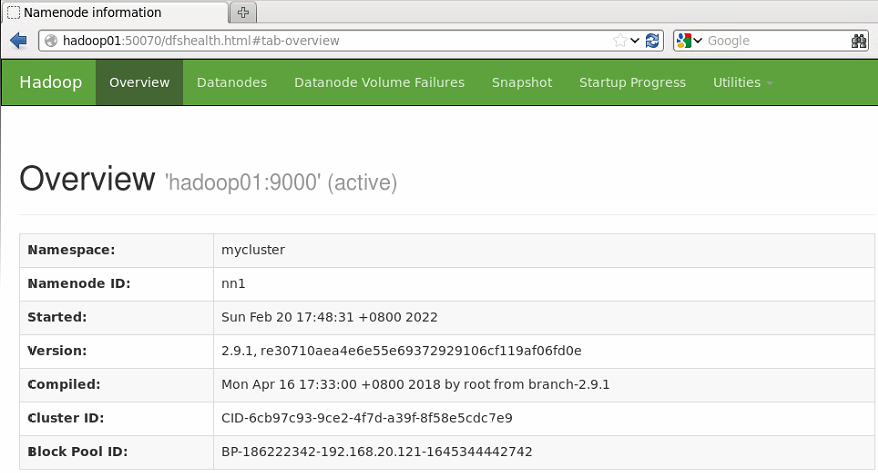
浏览器输入http://hadoop01:50070
该节点的状态为active,表示HDFS可以通过hadoop01节点的NameNode对外提供服务。
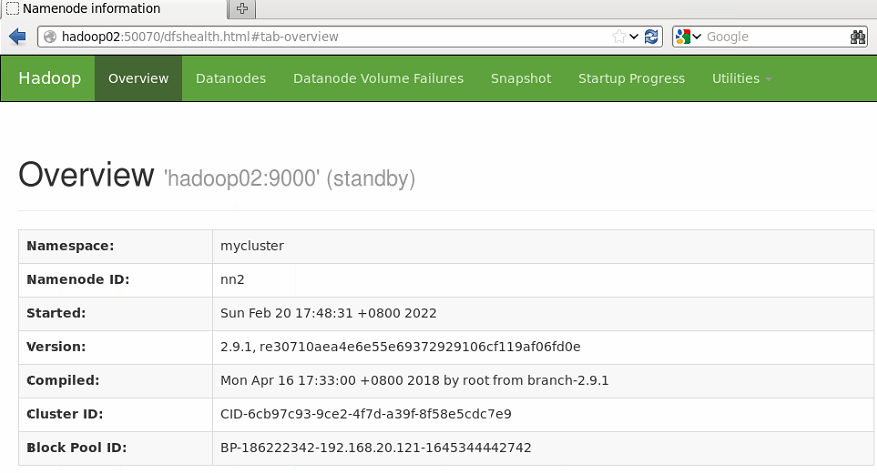
浏览器输入http://hadoop02:50070
该节点的状态为standby,表示HDFS不能对外提供服务,只能作为备用节点。
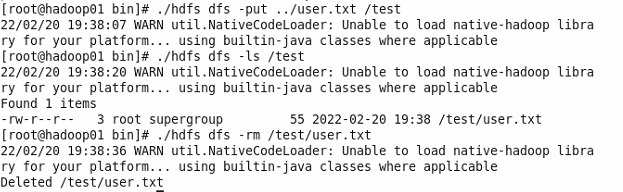
5、文件写入测试。
(1)在hadoop目录创建一个user.txt文件。
(2)在HDFS上创建一个文件目录。
./hdfs dfs -mkdir /test
(3)向HDFS上传一个文件。
./hdfs dfs -put ../user.txt /test
(4)查看user.txt是否上传成功。
./hdfs dfs -ls /test
(5)删除文件。
./hdfs dfs -rm /test/user.txt