
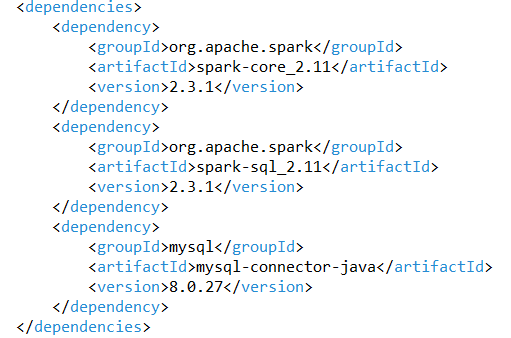
1、maven依赖。
2、测试代码。
package spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
public class DBApp {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("MySQLSpark");
JavaSparkContext sparkContext = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sparkContext);
// 写入mysql数据
writeMySQL(sparkContext, sqlContext);
// 读取mysql数据
//readMySQL(sqlContext);
// 停止SparkContext
sparkContext.stop();
}
/**
* 读取数据
* @param sqlContext
*/
private static void readMySQL(SQLContext sqlContext) {
String url = "jdbc:mysql://localhost:3306/world";
// 查找的表名
String table = "user";
// 数据库连接
Properties connProperties = new Properties();
connProperties.put("user", "root");
connProperties.put("password", "123456");
connProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// SparkJdbc读取MySQL的user表内容
System.out.println("读取world数据库中的user表内容");
// 读取表中所有数据
Dataset<Row> dsUser = sqlContext.read().jdbc(url, table, connProperties).select("*");
// 显示数据
dsUser.show();
}
/**
* 写入数据
* @param sparkContext
* @param sqlContext
*/
private static void writeMySQL(JavaSparkContext sparkContext, SQLContext sqlContext) {
String url = "jdbc:mysql://localhost:3306/world";
// 查找的表名
String table = "user";
// 数据库连接
Properties connProperties = new Properties();
connProperties.put("user", "root");
connProperties.put("password", "123456");
connProperties.put("driver", "com.mysql.cj.jdbc.Driver");
// 写入的数据内容
JavaRDD<String> sourceRDD = sparkContext.parallelize(Arrays.asList("tom a", "jack b", "alex c"));
// 第一步:在RDD的基础上创建类型为Row的RDD。
// 将RDD变成以Row为类型的RDD。Row可以简单理解为Table的一行数据。
JavaRDD<Row> userRDD = sourceRDD.map(new Function<String, Row>() {
public Row call(String line) throws Exception {
String[] splited = line.split(" ");
return RowFactory.create(splited[0], splited[1]);
}
});
// 第二步:动态构造DataFrame的元数据。
List structFields = new ArrayList();
structFields.add(DataTypes.createStructField("name", DataTypes.StringType, true));
structFields.add(DataTypes.createStructField("desc", DataTypes.StringType, true));
// 构建StructType,用于最后DataFrame元数据的描述。
StructType structType = DataTypes.createStructType(structFields);
// 第三步:基于已有的元数据以及RDD<Row>来构造DataFrame。
Dataset dsDateset = sqlContext.createDataFrame(userRDD, structType);
// 第四步:将数据写入到user表中。
dsDateset.write().mode("append").jdbc(url, table, connProperties);
}
}