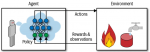
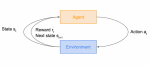
Gym CartPole 倒立摆 随机策略
import gym
import matplotlib.pyplot as plt
# 1. 产生环境
# env = gym.make(‘CartPole-v0’)
# 注意 gym 新版本 需要说明 render_mode
env = gym.make(‘CartPole-v1’, render_mode=”human”)
# 2. 可视化:回报曲线变化图,回报直方图
# figsize=(a, b) 用来设置图形的大小,a为图形的宽,b