
数据湖是一个集中式存储库,可存储任意规模结构化和非结构化数据,支持大数据和AI计算。数据湖构建(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户快速地构建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
1、开源生态构建数据湖
用户已经基于阿里云开源大数据生态系统(E-MapReduce,实时计算Flink,DLA等产品)来构建自己的数据处理分析平台,而在数据量飞速膨胀的趋势下,用户存储资源与计算资源扩容速度不匹配,有成本优化方面的诉求;大数据生态的丰富,用户的数据来源广泛,元数据分散较难管理,用户希望能统一管理不同存储中的元数据。
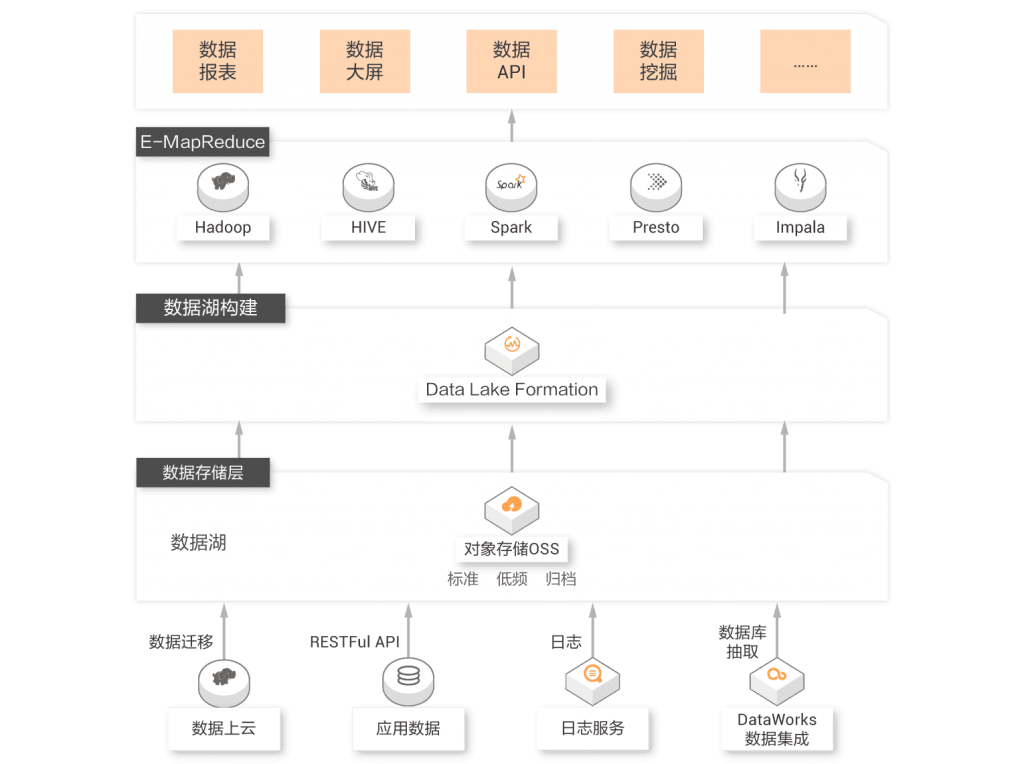
2、构建湖仓一体数据仓库
数据仓库和数据湖,是大数据架构的两种设计取向。数据湖优先的设计,通过开放底层文件存储,给数据入湖带来了最大的灵活性。而数据仓库优先的设计,更加关注的是数据使用效率、大规模下的数据管理、安全/合规这样的企业级成长性需求。灵活性和成长性,对于处于不同时期的企业来说,重要性不同。随着用户业务的逐渐清晰与沉淀,用户面临着数据湖和数据仓库架构的融合,依托于阿里云数据仓库(MaxCompute、Hologres、ADB等产品)和数据湖构建产品,帮助用户打造湖仓一体的数据系统,让数据和计算在湖和仓之间自由流动,从而构建一个完整的有机的大数据技术生态体系。
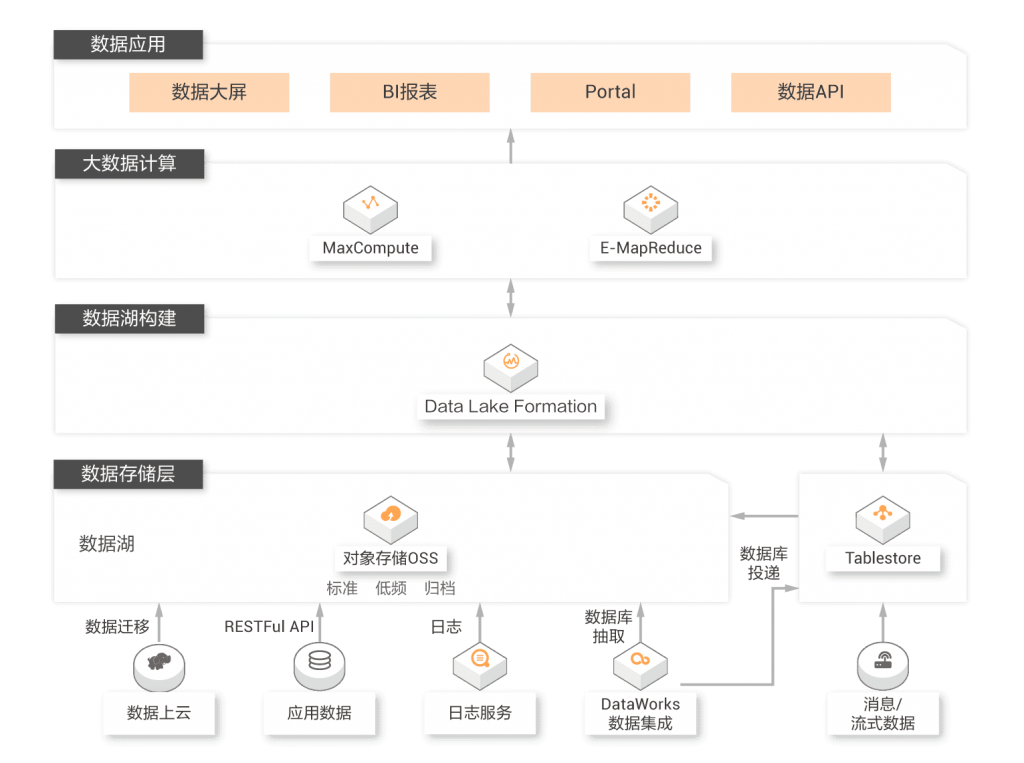
3、数据湖数据实时分析
用户大量不同类型数据存储在OSS中,希望能对数据做各种多种维度的分析查询,如实时数据分析、OLAP查询,并将对应的结果反馈到业务系统中。同时用户希望能方便的对接云上多种计算引擎,在数据查询时能够直接进行,不需要提取全部数据到查询系统。

4、数据湖构建机器学习
大数据是AI的基础,AI也是大数据的未来。数据湖可以很好的在经典机器学习场景和深度学习场景下服务用户:在机器学习场景下,用户面临数据量大,模型训练慢,算法效果差的问题,需要数据湖具备能够对接成熟的机器学习平台的能力。在深度学习时,用户需要能够动态的调整对GPU资源的使用,节约成本。
