PyTorch 激励函数 Sigmoid ReLU Tanh
一、Sigmoid ReLU Tanh 定义
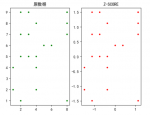
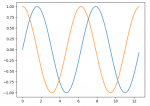
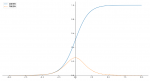
1、Sigmoid。Sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
import torch
import matplotlib
import matplotlib.pyplot as plt
import math
plt.figure(figsize=(15,8))
# 指定默认字体
matplotlib.