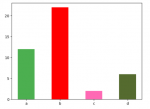
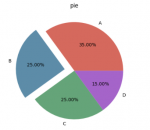
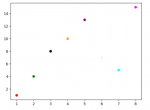
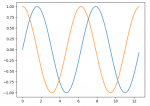
标量、向量、矩阵、张量之间的区别和联系

标量(Scalar)、向量(Vector)、矩阵(Matrix)、张量(Tensor)。
1、标量
标量(scalar):一个标量就是一个单独的数(整数或实数),不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。
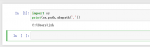
在Python中的定义为:
x = 1
2、向量
向量(vector):一个向量表示一组有序排列的数,通过次序中的索引我们能够找到每个单独的数。向量中的每个元素就是一个标量,向量中的第i个元素用表示。
在Python中的定义为:
imp