
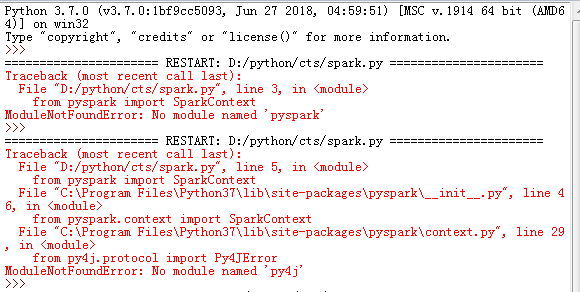
1、如果遇到“No module named pyspark”,则需要将py4j、pyspark拷贝至Python37\Lib\site-packages。
将D:\bigdata\spark-2.3.2-bin-hadoop2.7\python\lib目录下的
py4j-0.10.7-src.zip和pyspark.zip
解压缩、拷贝至C:\Program Files\Python37\Lib\site-packages目录下。
2、启动spark-shell
D:\bigdata\spark-2.3.2-bin-hadoop2.7\bin\spark-shell.cmd
3、测试代码。spark.py
如果测试代码spark.py无法正常运行,则将spark.py拷贝至D:\bigdata\spark-2.3.2-bin-hadoop2.7\examples\src\main\python,再次尝试。
#coding=utf-8
from pyspark import *
# Create SparkConf
conf = SparkConf().setAppName("WordCount").setMaster("local")
# Create SparkContext
sc = SparkContext(conf=conf)
# 从本地模拟数据
datas = ["jzh, car", "jzh, house", "idodo, house"]
# Create RDD
rdd = sc.parallelize(datas)
print("记录条数:" + str(rdd.count()))
#print(rdd.first())
# WordCount
# rdd.flatMap(lambda line: line.split(",")) \ # 字符串进行分割
# map(lambda word: (word, 1)) \ # 映射为(word,1)元祖,例如 (jzh,1 ) (car,1 )
# reduceByKey(lambda a, b: a + b) # 将Key相同的Value进行合并
wordcount = rdd.flatMap(lambda line: line.split(",")) \
.map(lambda word: (word, 2)) \
.reduceByKey(lambda a, b: a + b)
# collect()函数将rdd转换为列表
for wc in wordcount.collect():
print(wc[0] + ":出现次数" + str(wc[1]))