
import gym
import matplotlib.pyplot as plt
# 1. 产生环境
# env = gym.make('CartPole-v0')
# 注意 gym 新版本 需要说明 render_mode
env = gym.make('CartPole-v1', render_mode="human")
# 2. 可视化:回报曲线变化图,回报直方图
# figsize=(a, b) 用来设置图形的大小,a为图形的宽,b为图形的高,单位为英寸。
fig = plt.figure('CartPole', figsize=(5.0, 2.5))
ax = fig.add_subplot()
# 2.1 可视化函数
def plt_result(total_reward): #
# 子图:训练过程中,每回合的总奖励 曲线变化图
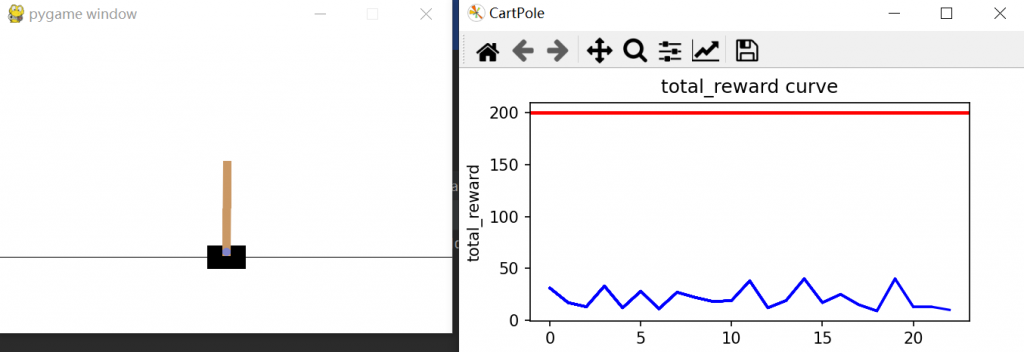
ax.plot(total_reward, c='b', label='total_reward per episode')
ax.axhline(200, c='r', label='goal') # 参考线,根据经验平均能达到200
ax.set_xlabel('episode')
ax.set_ylabel('total_reward')
ax.set_title('total_reward curve')
# 暂停 产生动态效果
plt.pause(0.001)
# 3. 测试 纯随机策略,做为参照。
def random_policy(env, n_episode):
rewards = []
for ep in range(n_episode):
# 3.1 每个回合,都先重置环境
env.reset()
# 3.2 初始化
total_reward, done = 0, False
# 3.3 随机探索,直到环境认为结束:对于CartPole-v1来说,小车位置在+-2.4范围之内而且杆的倾斜成都没有超过24°
while not done:
# 3.3.1 渲染环境
env.render()
# 3.3.2 选择动作
a = env.action_space.sample() # 没有策略,所以只能纯随机
# s_, r, done, _ = env.step(a) # s_:下一状态 r:产生的即时奖励 done:环境认为达到终止条件
# 注意 gym 新版本 env.step 返回的参数从4个变为5个
s_, r, done, truncated, info = env.step(a)
total_reward += r
# 3.4 记录本回合的总奖励
rewards.append(total_reward)
# 3.5 可视化回合总奖励曲线
plt_result(rewards)
# 3.1 测试 纯随机策略
random_policy(env, 50)
【2023-03-18 更新】
Observation:
Type: Box(4)
Num Observation Min Max
0 Cart Position -4.8 4.8
1 Cart Velocity -Inf Inf
2 Pole Angle -0.418 rad (-24 deg) 0.418 rad (24 deg)
3 Pole Angular Velocity -Inf Inf
Actions:
Type: Discrete(2)
Num Action
0 Push cart to the left
1 Push cart to the rightrad 弧度 deg 角度。
1弧度=180/π≈57.3度
1度=π/180≈0.01745弧度
# 环境:gym 小车倒立摆模型,目标是使系统稳定在 中心点 附近
# 状态空间:维度是4,包括 小车位置、小车速度、杆的倾斜角度、杆的角速度
# 动作空间:维度是2,包括 小车向左、小车向右
import gym
import matplotlib.pyplot as plt
# 1. 产生环境
# env = gym.make('CartPole-v0')
# 注意 gym 新版本 需要说明 render_mode
env = gym.make('CartPole-v1', render_mode="human")
# 2. 可视化:回报曲线变化图,回报直方图
# figsize=(a, b) 用来设置图形的大小,a为图形的宽,b为图形的高,单位为英寸。
fig = plt.figure('CartPole', figsize=(5.0, 2.5))
ax = fig.add_subplot()
# 2.1 可视化函数
def plt_result(total_reward): #
# 子图:训练过程中,每回合的总奖励 曲线变化图
ax.plot(total_reward, c='b', label='total_reward per episode')
ax.axhline(200, c='r', label='goal') # 参考线,根据经验平均能达到200
ax.set_xlabel('episode')
ax.set_ylabel('total_reward')
ax.set_title('total_reward curve')
# 暂停 产生动态效果
plt.pause(0.001)
# 3. 这部分是测试 纯随机 策略,不会有任何学习在里面,做参照用。
def random_policy(env, n_episode):
rewards = []
for ep in range(n_episode):
# 3.1 每个回合,都先重置环境
env.reset()
# 3.2 初始化
total_reward, terminated = 0, False
# 3.3 随机探索,直到环境认为结束:对于CartPole-v1来说,小车位置在+-2.4范围之内而且杆的倾斜成都没有超过24°
while not terminated:
# 3.3.1 渲染环境
env.render()
# 3.3.2 选择动作
a = env.action_space.sample() # 没有策略,所以只能纯随机
# s_, r, done, _ = env.step(a) # s_:下一状态 r:产生的即时奖励 done:环境认为达到终止条件
# 注意 gym 新版本 env.step 返回的参数从4个变为5个
# terminated:环境认为达到终止条件
# 将 动作 传递给环境
s_, r, terminated, truncated, info = env.step(a)
print('动作 = {0}: 当前状态 = {1}, 奖励 = {2}, 结束标志 = {3}, 日志信息 = {4}'.format(a, s_, r, terminated, info))
total_reward += r
# 3.4 记录本回合的总奖励
rewards.append(total_reward)
# 3.5 可视化回合总奖励曲线
plt_result(rewards)
# 3.1 测试 纯随机策略
random_policy(env, 50)
动作 = 0: 当前状态 = [ 0.00174629 -0.2374131 -0.03975308 0.24497807], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.00300197 -0.04174657 -0.03485352 -0.05997417], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.0038369 -0.2363519 -0.036053 0.22151169], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.00856394 -0.43094048 -0.03162277 0.5026076 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.01718275 -0.6256028 -0.02157062 0.78515947], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.0296948 -0.4301912 -0.00586743 0.48576903], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.03829863 -0.62522984 0.00384795 0.77659696], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.05080323 -0.8204045 0.01937989 1.0704881 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.06721132 -0.62554413 0.04078966 0.78394973], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.0797222 -0.82120216 0.05646865 1.0891815 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.09614624 -1.0170213 0.07825228 1.399035 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.11648666 -0.8229545 0.10623298 1.1318083 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.13294576 -0.62937135 0.12886915 0.87424433], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.14553317 -0.43621477 0.14635403 0.62469476], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.15425748 -0.633044 0.15884793 0.9596569 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [-0.16691835 -0.8299034 0.17804107 1.2977335 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.18351643 -0.637432 0.20399573 1.065658 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [-0.19626507 -0.445507 0.2253089 0.84329957], 奖励 = 1.0, 结束标志 = True, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.03008589 0.16314174 -0.03753547 -0.31906262], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.03334872 0.3587776 -0.04391672 -0.6233426 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.04052427 0.55448437 -0.05638358 -0.929527 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.05161396 0.7503202 -0.07497411 -1.2393819 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [ 0.06662036 0.55623686 -0.09976175 -0.9710966 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [ 0.0777451 0.36258513 -0.11918368 -0.7113445 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.0849968 0.5591382 -0.13341057 -1.0390397 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [ 0.09617957 0.36601683 -0.15419137 -0.7910382 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.1034999 0.5628817 -0.17001213 -1.127985 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 0: 当前状态 = [ 0.11475754 0.37034452 -0.19257183 -0.89308614], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
动作 = 1: 当前状态 = [ 0.12216443 0.5674832 -0.21043356 -1.2395949 ], 奖励 = 1.0, 结束标志 = True, 日志信息 = {}
动作 = 0: 当前状态 = [-0.02721931 -0.23370105 -0.02964729 0.3122524 ], 奖励 = 1.0, 结束标志 = False, 日志信息 = {}
s_ 默认返回的是弧度。