
一、创建应用
打开 Visual Studio 并新建 .NET 控制台应用:
1、从 Visual Studio 2022 开始窗口中选择 新建项目。
2、选择 C# 控制台应用 项目模板。
3、将项目名称更改为 MLApp。
4、确保不选中将解决方案和项目置于同一目录中。
5、选择“下一步”按钮。
6、选择 .NET Framework 4.8。
7、选择“创建”按钮。Visual Studio 将创建项目并加载 Program.cs 文件。
二、添加机器学习
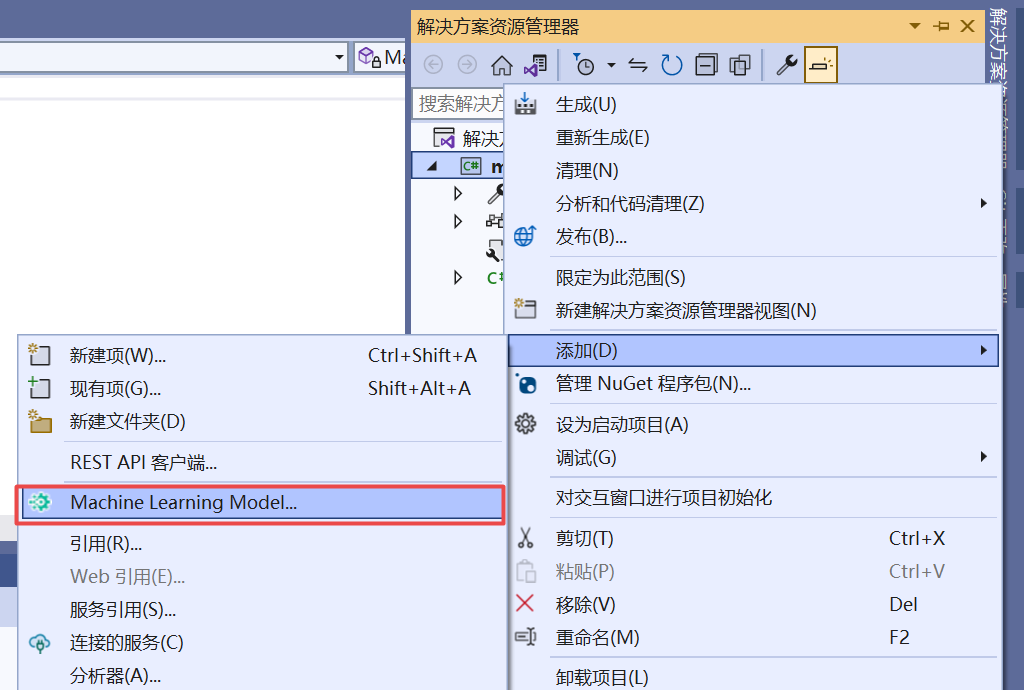
1、右击 解决方案资源管理器 中的 myMLApp 项目,并选择 添加 > 机器学习模型。
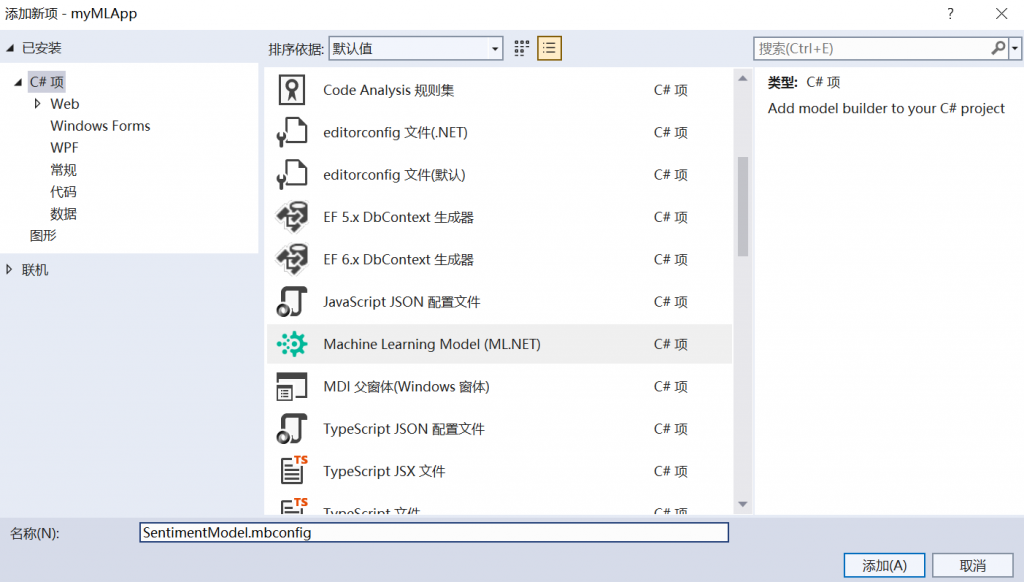
2、在“添加新项目”对话框中,确保选中“机器学习模型(ML.NET)”。
3、将“名称”字段更改为 SentimentModel.mbconfig,然后选择“添加”按钮。一个名为 SentimentModel.mbconfig 的新文件将添加到你的解决方案中,并且 Model Builder UI 将在 Visual Studio 的新停靠工具窗口中打开。mbconfig 文件只是一个 json 文件,用于跟踪 UI 的状态。
三、选取方案
若要生成模型,首先需要选择机器学习场景。Model Builder 支持多种场景:
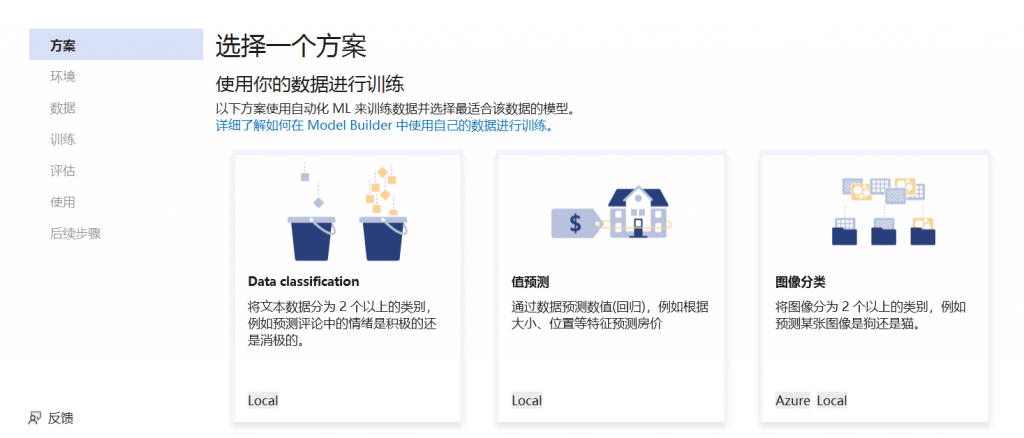

在这种情况下,将根据客户评价的内容(文字)预测情绪。
1、在“Model Builder 方案”屏幕中,选择数据分类 方案,因为要预测注释属于哪个类别(正或负)。
2、在选择 数据分类方案后,必须选择训练环境。虽然一些方案支持在 Azure 中进行训练,但“分类”目前仅支持本地训练,因此,请保持选择 本地 环境,并继续执行 数据 步骤。

四、下载并添加数据
下载 UCI 机器学习存储库中的带情绪标签的句子数据集。解压缩 sentiment labelled sentences.zip 并保存 yelp_labelled.txt 文件到 myMLApp 目录。
yelp_labelled.txt 中的每一行代表用户在 Yelp 上对餐厅的不同评论。第一列代表用户留下的评论,第二列代表文本的情绪(0 为负面,1 为正面)。这些列由制表符分隔,并且数据集没有标头。数据如下所示:
Wow... Loved this place. 1
Crust is not good. 0
Not tasty and the texture was just nasty. 0添加数据
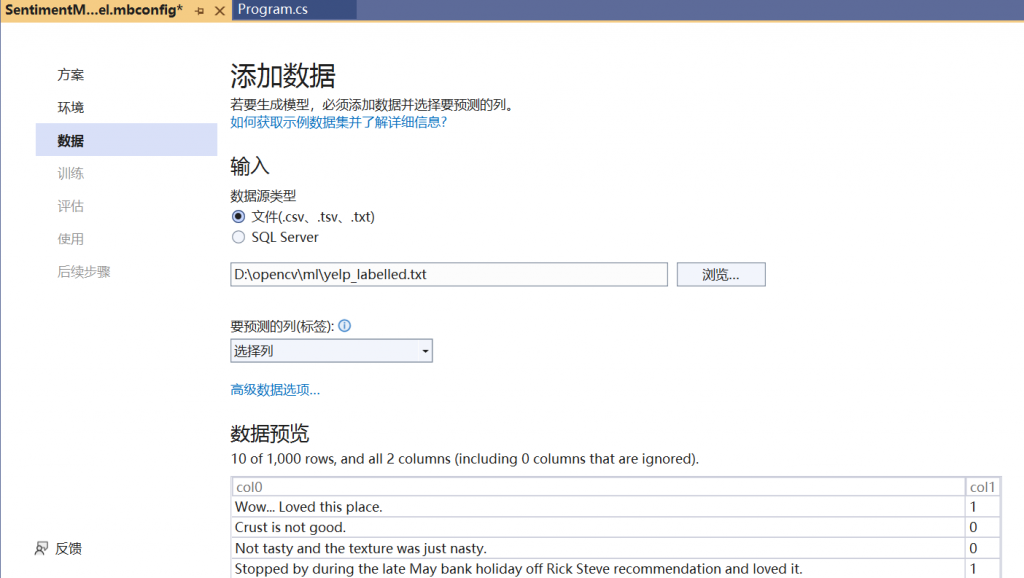
在 Model Builder 中,可以从本地文件添加数据或连接到 SQL Server 数据库。这次你将从文件添加 yelp_labelled.txt。
1、选择 文件 作为输入数据源类型。
2、浏览 yelp_labelled.txt。选择数据集后,数据预览会显示在 数据预览 部分中。由于数据集没有标头,因此将自动生成标头(“col0” 和 “col1”)。
3、在“预测列 (标签)”下,选择 “col1″。“标签”是预测内容,在本例中是在数据集的第二列 (“col1”) 中发现的情绪。
4、用于帮助预测标签的列称为“特征”。除“标签”外,数据集中的所有列都将自动选择为“特征”。在这种情况下,审阅评论列(“col0”)是特征列。可以在“高级数据选项”中更新特征列并修改其他数据加载选项,但在本示例中不是必需的。
五、训练模型
现在,将使用 yelp_labelled.txt 数据集来训练模型。
Model Builder 会根据生成性能最佳模型给定的定型时间,评估多个具有不同算法和设置的模型。
1、将“训练时间”(即希望 Model Builder 探索各种模型的时间)更改为 60 秒(如果训练后未发现模型,则可以尝试增加此数字)。请注意,对于较大的数据集,训练时间会更长。Model Builder 会根据数据集大小自动调整训练时间。
2、选择开始训练以开始训练过程。训练开始后,可以看到剩余时间。

训练结果
完成训练后,你可以查看训练结果摘要。
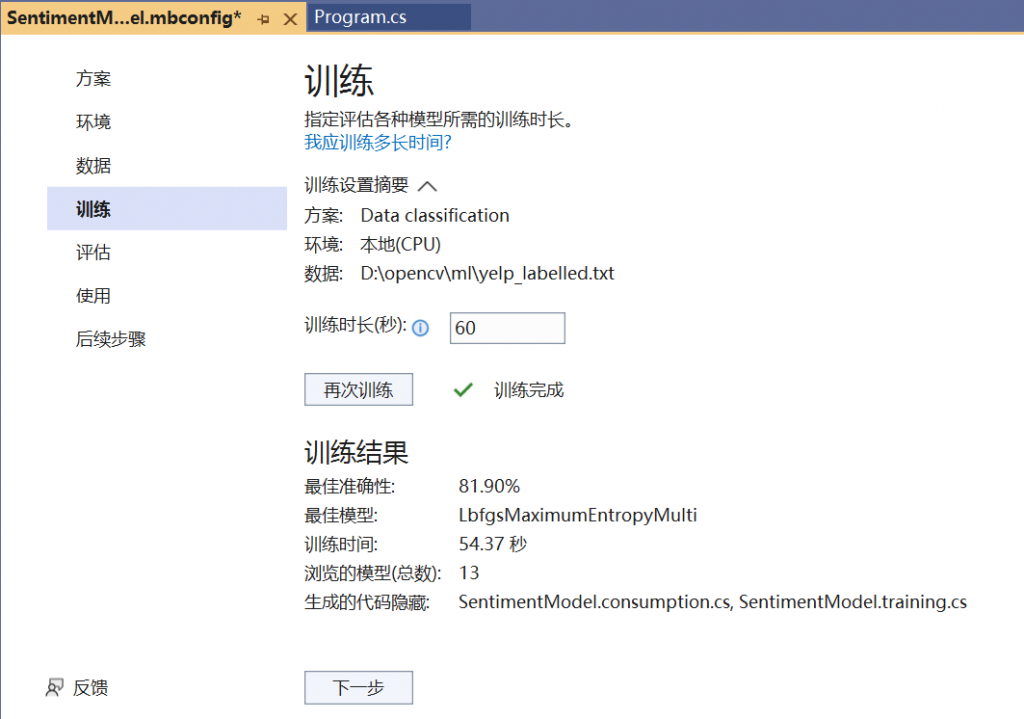
最佳准确性 – 这将向你展示 Model Builder 找到的最佳模型的准确性。精度越高意味着模型对于测试数据的预测越正确。
最佳模型 – 这将显示在 Model Builder 探索期间表现最佳的算法。
训练时间 – 显示训练/探索模型所花费的总时间量。
六、评估模型
评估步骤显示性能最佳的算法以及最佳准确度,并让你在 UI 中尝试相应模型。
立即试用模型
可以在“试用模型”部分对样本输入进行预测。文本框中预先填充了数据集的第一行数据,但你可以更改输入并选择“预测”按钮来尝试不同的情绪预测。
在这种情况下,0 表示负面情绪,1 表示正面情绪。
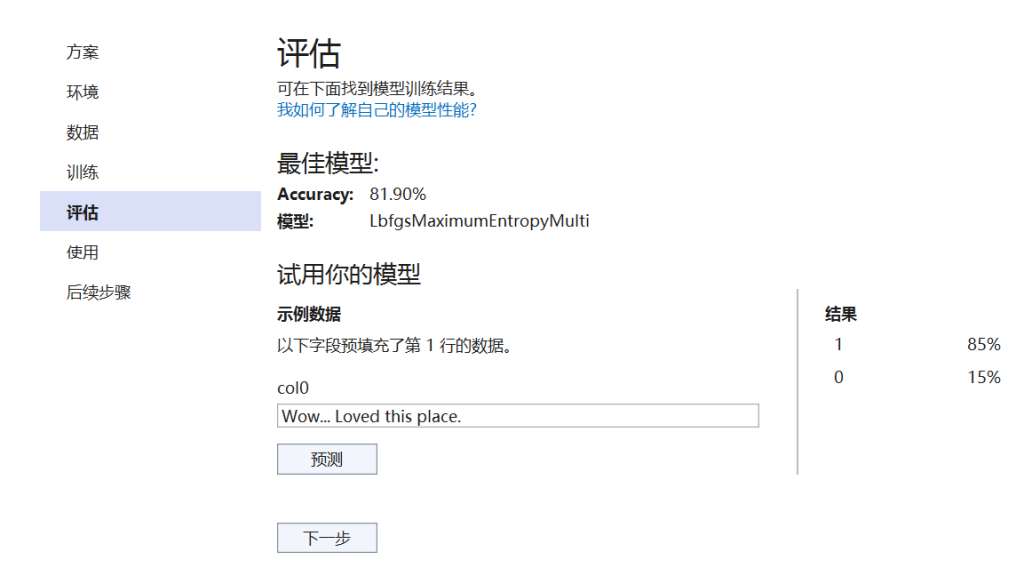
注意: 如果模型性能不佳(例如,如果“准确度”低或模型仅预测 ‘1’ 值),则可以尝试添加更多时间并再次训练。这是使用极小数据集的示例;对于生产级模型,需要添加更多的数据和训练时间。
七、生成代码
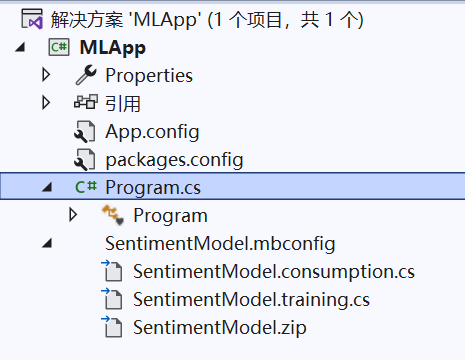
训练完成后,三个文件将作为代码隐藏自动添加到 SentimentModel.mbconfig 中:
SentimentModel.zip: 该文件是经过训练的 ML.NET 模型,它是一个序列化的 zip 文件。SentimentModel.consumption.cs: 此文件包含模型输入和输出类以及可用于模型消耗的Predict方法。SentimentModel.training.cs: 此文件包含用于训练最终模型的训练管道(数据转换、算法和算法参数)。
在 Model Builder 的 Consume 步骤中,提供了一个代码片段,用于为模型创建样本输入并使用模型对该输入进行预测。
Model Builder 还提供了项目模板,可以选择将其添加到解决方案中。有两个项目模板(一个控制台应用和一个 Web API)使用经过训练的模型。

八、使用模型
最后一步是在最终用户应用程序中使用经过训练的模型。
1、在 MLApp 项目 Program.cs 的 void Main(string[] args) 加入以下代码:
// Add input data
var sampleData = new SentimentModel.ModelInput()
{
Col0 = "This restaurant was wonderful."
};
// Load model and predict output of sample data
var result = SentimentModel.Predict(sampleData);
// If Prediction is 1, sentiment is "Positive"; otherwise, sentiment is "Negative"
var sentiment = result.PredictedLabel == 1 ? "Positive" : "Negative";
Console.WriteLine($"Text: {sampleData.Col0}\nSentiment: {sentiment}");
2、运行 MLApp (选择“Ctrl+F5”或“调试”>“在不调试的情况下启动”)。应看到以下输出,内容为预测输入语句是正的还是负的。
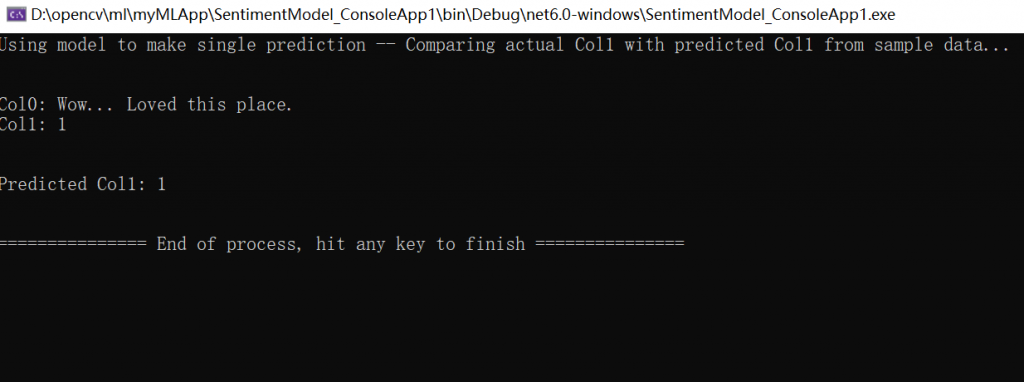
特殊说明:如果训练完成后(三个文件),无法识别C#代码文件,则在第七个环节(七、生成代码)Console App 添加到解决方案进行测试。
// This file was auto-generated by ML.NET Model Builder.
using System;
namespace SentimentModel_ConsoleApp
{
class Program
{
static void Main(string[] args)
{
// Create single instance of sample data from first line of dataset for model input
SentimentModel.ModelInput sampleData = new SentimentModel.ModelInput()
{
Col0 = @"Wow... Loved this place.",
};
// Make a single prediction on the sample data and print results
var predictionResult = SentimentModel.Predict(sampleData);
Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n");
Console.WriteLine($"Col0: {@"Wow... Loved this place."}");
Console.WriteLine($"Col1: {1F}");
Console.WriteLine($"\n\nPredicted Col1: {predictionResult.Prediction}\n\n");
Console.WriteLine("=============== End of process, hit any key to finish ===============");
Console.ReadKey();
}
}
}