
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels (int) – 输入图像中的通道数
out_channels (int) – 卷积产生的通道数即输出图片的通道数
kernel_size (int or tuple) – 卷积核的大小(可以是个数,也可以是元组)
stride (int or tuple, optional) — 卷积的步幅。 默认值:1
padding (int, tuple or str, optional) – 填充添加到输入的所有四个边。 默认值:0
dilation (int or tuple, optional) – 内核元素之间的间距。 默认值:1。
groups (int, optional) – 分组卷积。 默认值:1
bias (bool, optional) — 如果为true,则为输出添加可学习的偏差。 默认值:true
padding_mode (string, optional) –填充的几个选择 ‘zeros’, ‘reflect’, ‘replicate’ 或 ‘circular’。 默认值:“zeros”
一、关于dilation的补充说明
Pytoch中dilation默认等于1,但是实际为不膨胀,也就是说设置dilation = 2 时才会真正进行膨胀操作。
1、我们定义一个3 * 3的卷积核,如果dilation参数为默认(1),那就是按照常规理解来做卷积,如下图所示。
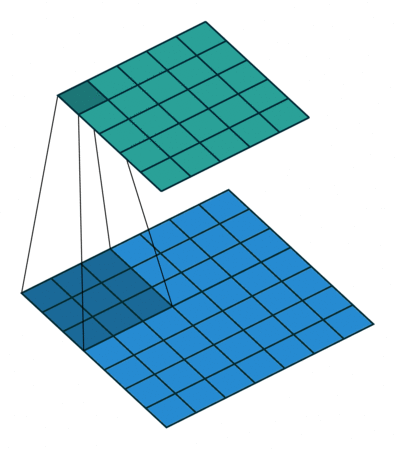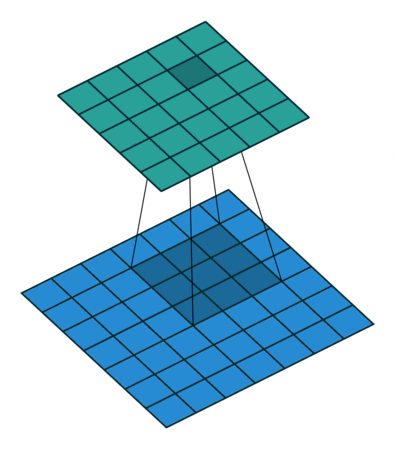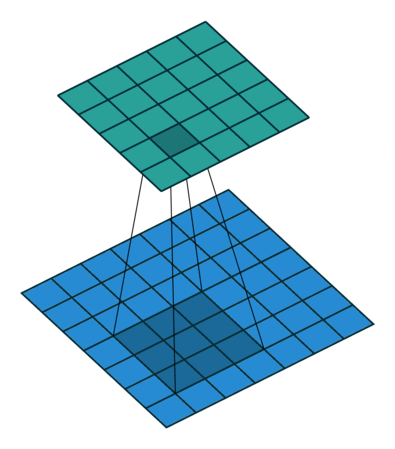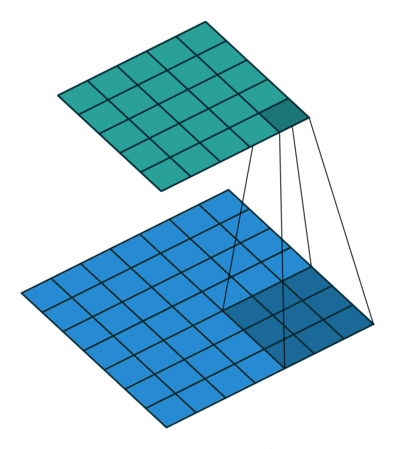
import torch
import torch.nn as nn
m = nn.Conv2d(1, 1, (3, 3), dilation=(1, 1)) # dilation=(1,1) 等价于 dilation=1
input = torch.randn(1, 1, 7, 7)
print('input.shape', input.shape)
output = m(input)
print('output.shape', output.shape)
input.shape torch.Size([1, 1, 7, 7]) output.shape torch.Size([1, 1, 5, 5])
2、如果我们把dilation设置成2,其实也就是在两两卷积点中插入一个空白,使得3*3的卷积核,变为了5 * 5,如下图所示。
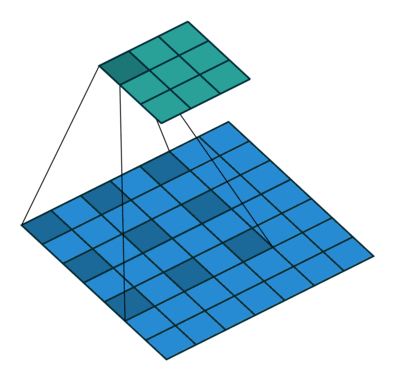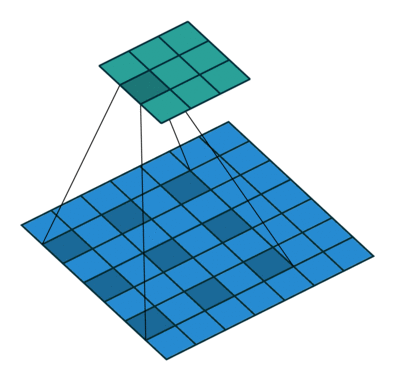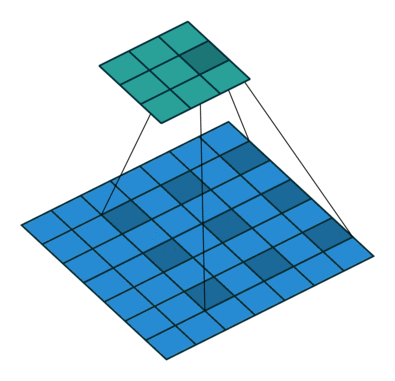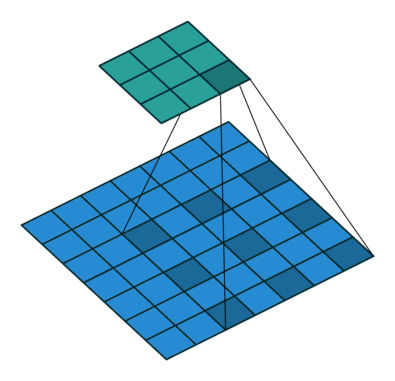
import torch
import torch.nn as nn
m = nn.Conv2d(1, 1, (3, 3), dilation=(2, 2)) # dilation=(2,2) 等价于 dilation=2
input = torch.randn(1, 1, 7, 7)
print('input.shape', input.shape)
output = m(input)
print('output.shape', output.shape)
input.shape torch.Size([1, 1, 7, 7]) output.shape torch.Size([1, 1, 3, 3])
二、关于卷积前后的尺寸大小说明
nn.Conv2d 的功能是:对由多个输入平面组成的输入信号进行二维卷积。
输入信号的形式为(N,Cin,H,W)。N表示batch size,即N个样本。C表示channel个数。H,W分别表示特征图的高和宽。
如果将 feature map shape,比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有W 个字符。

输入图片大小:W*H
滤波器(卷积核大小,kernel_size):F*F
滑动步长(stride):S
padding的像素数:P
输出图片大小:W_n * H_n
W_n= (W+2P-F)/S + 1
H_n = (H+2P-F)/S + 1
以上针对卷积层的操作,忽略图片的通道数,当除不尽时,向下取整。