
聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。 实现聚类分析的计算方法称为聚类算法,在机器学习中是涉及对数据进行分组的一种算法,即在给定的数据集中,我们通过聚类算法将其分成一些不同的组。在理论上,相同的组的数据之间有相同的属性或者是特征,不同组数据之间的属性或者特征相差就会比较大。聚类算法是一种非监督学习算法,并且作为一种常用的数据分析算法在很多领域上得到应用。
K-means聚类算法是最常用的聚类算法。它在许多的工业级数据科学和机器学习中被广泛应用,并且容易理解和实现。 算法步骤: (1)首先,我们确定要聚类的数量,并随机初始化它们各自的中心点。为了确定要聚类的数量,最好快速查看数据并尝试识别任何不同的分组。中心点是与每个数据点向量长度相同的向量。这需要我们提前预知类的数量(即中心点的数量)。
(2)计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类中。
(3)计算每一类内,所有点的平均值,作为新簇中心。
(4)重复以上步骤,直到每一类中心在每次迭代后变化不大为止。也可以多次随机初始化中心点,然后选择运行结果最好的一个。
scikit-learn聚类算法通过sklearn.cluster包实现,涉及KMeans,MiniBatchKMeans,Birch,DBSCAN,SpectralClustering,AffinityPropagation六种算法。
|
列名 |
说明 |
数据类型 |
| SepalLength | 花萼长度 | float |
| SepalWidth | 花萼宽度 | float |
| PetalLength | 花瓣长度 | float |
| PetalLength | 花瓣宽度 | float |
| Class | 类别。0表示山鸢尾(Iris-setosa)、1表示变色鸢尾(Iris-versicolor)、2表示维吉尼亚鸢尾(Iris-virginica) | int |
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
# 鸢尾花数据集
iris = load_iris()
# 指定类别、迭代次数
model = KMeans(n_clusters=3, max_iter=10)
model.fit(iris.data)
print('聚类中心:', model.cluster_centers_)
print('每个样本所属的簇:', model.labels_)
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
# 绘图函数
plt.scatter(iris.data[:, 0], iris.data[:, 1], c=model.labels_, cmap=cm_dark, s=20)
plt.show()
#print('iris数据集前5行的数据:',iris.data[:5])
#print('iris数据集前5行的类别:',iris.target[:5])
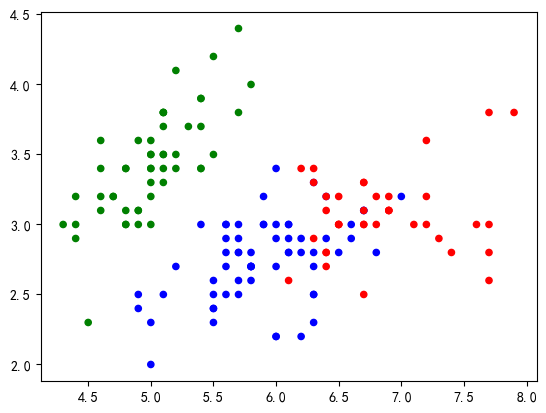
plt.scatter()函数用于生成一个scatter散点图。
x,y:每个散点对应的横纵坐标。
c:表示的是色彩或颜色序列,可选,默认蓝色b。c可以是一个RGB或RGBA二维行数组。
cmap:colormap,cmap仅仅当c是一个浮点数数组的时候才使用。
s:散点的大小。