
3台linux虚拟机,主机名分别为hadoop01、hadoop02和hadoop03。
1、启动hdfs集群(使用hadoop的批量启动脚本)。
/home/hadoop/app/hadoop/sbin/start-dfs.sh
2、停止hdfs集群(使用hadoop的批量启动脚本)。
/home/hadoop/app/hadoop/sbin/stop-dfs.sh
3、启动单个进程。
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start namenode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start datanode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start zkfc
4、查看进程。
jps
5、停止单个进程。
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop namenode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop datanode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode
/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop zkfc
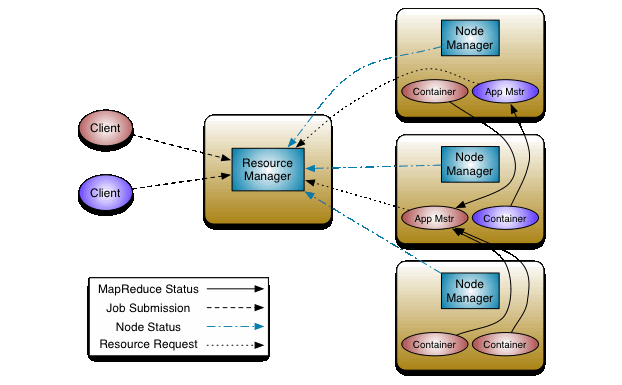
6、启动yarn集群(使用hadoop的批量启动脚本)。启动yarn之前需要确保zookeeper已经启动(cd /home/hadoop/app/zookeeper/bin)(./zkServer.sh start)。
/home/hadoop/app/hadoop/sbin/start-yarn.sh
7、启动hadoop02上的ResourceManager进程。start-yarn.sh启动脚本只在本地启动一个ResourceManager进程,而3台机器上的nodemanager都是通过ssh的方式启动的。所以hadoop02机器上的ResourceManager需要我们手动去启动。
/home/hadoop/app/hadoop/sbin/yarn-daemon.sh start resourcemanager
8、停止yarn。
/home/hadoop/app/hadoop/sbin/stop-yarn.sh
9、停止hadoop02上的resourcemanager。
stop-yarn.sh脚本只停止了本地的那个ResourceManager进程,所以hadoop02上的那个resourcemanager我们需要单独去停止。
/home/hadoop/app/hadoop/sbin/yarn-daemon.sh stop resourcemanager
10、查看 RM 状态。
/home/hadoop/app/hadoop/bin/yarn rmadmin -getServiceState rm1
/home/hadoop/app/hadoop/bin/yarn rmadmin -getServiceState rm2
11、Web 界面查看 yarn。
http://hadoop01:8088
http://hadoop02:8088
12、测试运行 yarn。
运行 Hadoop 自带 Wordcount 程序。
/home/hadoop/app/hadoop/bin/hadoop jar share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.10.0.jar wordcount /test/wd.txt /test/output
查看执行结果
/home/hadoop/app/hadoop/bin/hdfs dfs -cat /test/output/*