
假设有一场足球赛,我们有两支球队的所有出场球员信息、历史交锋成绩、比赛时间、主客场、裁判和天气等信息,根据这些信息预测球队的输赢。假设比赛结果记为y,赢球标记为1,输球标记为0,这就是典型的二元分类问题,可以用逻辑回归算法来解决。与线性回归算法的最大区别是,逻辑回归算法的输出是个离散值。 1.预测函数 需要找出一个预测函数模型,使其值输出在[0,1]之间。然后选择一个基准值,如0.5,如果算出来的预测值大于0.5,就认为其预测值为1,反之,则其预测值为0。 选择Sigmoid函数(也称为Logistic函数,逻辑回归的名字由此而来)。
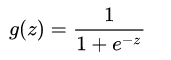

使用Logistic逻辑回归算法解决乳腺癌检测问题。我们需要先采集肿瘤病灶造影图片,然后对图片进行分析,从图片中提取特征,再根据特征来训练模型。最终使用模型来检测新采集到的肿瘤病灶造影,以便判断肿瘤是良性的还是恶性的。这是个典型的二元分类问题。 为了简单起见,直接加载scikit-learn自带的一个乳腺癌数据集。这个数据集是已经采集后的数据,数据集中总共有569个样本,每个样本有30个特征,其中357个阳性(y=1)样本,212个阴性(y=0)样本。打印出这30个特征的名称和一个样本数据,以便直观地进行观察。这30个特征是怎么来的呢?这个数据集总共从病灶造影图片中提取了以下10个关键属性:
radius:半径,即病灶中心点离边界的平均距离。
texture:纹理,灰度值的标准偏差。
perimeter:周长,即病灶的大小。
area:面积,也是反映病灶大小的一个指标。
smoothness:平滑度,即半径的变化幅度。
compactness:密实度,周长的平方除以面积,再减去1,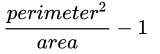
concavity:凹度,凹陷部分轮廓的严重程度。
concave points:凹点,凹陷轮廓的数量。
symmetry:对称性。
fractal dimension:分形维度。 然后又构造出了每个特征的标准差及最大值,这样每个特征就衍生出两个特征,总共30个特征。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import warnings
warnings.filterwarnings("ignore")
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
model = LogisticRegression()
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
print('matchs:{0}/{1}'.format(np.equal(y_pred,y_test).shape[0],
y_test.shape[0]))