数据预处理 z-score 标准化

μ为所有样本数据的均值。 σ为所有样本数据的标准差。
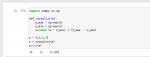
import numpy as np
#min-max 标准化
def normalize(x):
x_max = np.max(x)
x_min = np.min(x)
return (x – x_min) / (x_max
– x_min)
#z-score 标准化
def standardize(x):
ave = np.average(x)
std = np.std(x)
return

μ为所有样本数据的均值。 σ为所有样本数据的标准差。
import numpy as np
#min-max 标准化
def normalize(x):
x_max = np.max(x)
x_min = np.min(x)
return (x – x_min) / (x_max
– x_min)
#z-score 标准化
def standardize(x):
ave = np.average(x)
std = np.std(x)
return
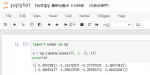
Min-Max normalization也称离差标准化法,是消除变量量纲和变异范围影响最简单的方法。对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
import numpy as np
def normalize(x):
x_max = np.max(x)
x_min = np.min(x)
return (x – x_min) / (x_max
– x_min)
x = [14,6,7]
y = normalize(x)
print(
我们更经常会用到的np.random.randn(size)所谓标准正态分布(μ=0,σ=1),对应于numpy.random.normal(loc=0.0, scale=1.0, size=None)
loc:float 此概率分布的均值(对应着整个分布的中心centre)。
scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)。
size:int or tuple of ints 输出的shape,默认为None,只输

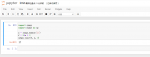
sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
import numpy as np
import matplotlib.pylab as plt
def sigmoid_function(x):
return 1/(1 + np.exp(-x))
x = np.linspace(-5, 5)
y = sigmoid_function(x)
plt.plot(
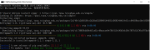
sympy.limit()
表达式:要对其执行极限运算的数学表达式,即 f(x)。
变量:数学表达式中的变量,即 x。
值:极限趋于的值,即 3。
import sympy
import numpy as np
x = sympy.Symbol(“x”)
f = 5*x + 2
sympy.limit(f, x, 3)
微积分的英语 “Calculus” 源自拉丁语,意思是 “小石头”,因为它是从分析小的部分来了解大的整体。
微分是把整体分拆为小部分来求它怎样改变。
积分是把小部分连接(积)在一起来求整体有多大。
1、导数是指 函数图像在某一点处的斜率,是纵坐标增量Δy和横坐标增量Δx在Δx>0时的比值。
2、微分是指 函数图像在某一点处的切线在横坐标取得增量Δx以后,纵坐标取得的增量,一般表示为dy。
3、积分是微分的逆运算,即知道了函数的导函数,反求原函数。
用SymPy库进行

这三种函数都是对数函数,对数函数的基本表示形式是:。式中a为对数的底数,y叫做真数。
如果a的x次方等于y(a>0,且a不等于1),那么数x叫做以a为底y的对数。
如果对数的底数为10,那么对数函数就可以写成“lg”,这种对数算法叫做“常用对数”。
如果对数的底数为e(自然常数),那么对数函数就可以写成“ln”,这种对数算法叫做“自然对数”。