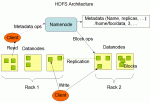
Hadoop集群之HDFS和YARN启动和停止命令
3台linux虚拟机,主机名分别为hadoop01、hadoop02和hadoop03。
1、启动hdfs集群(使用hadoop的批量启动脚本)。
/home/hadoop/app/hadoop/sbin/start-dfs.sh
2、停止hdfs集群(使用hadoop的批量启动脚本)。
/home/hadoop/app/hadoop/sbin/stop-dfs.sh
3、启动单个进程。
/home/hadoop/app/hadoop/sbin/hadoop-dae