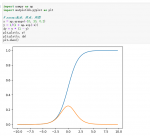
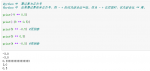
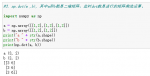
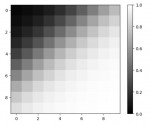
numpy np.random.shuffle(x)和np.random.permutation(x)数组打乱随机排列

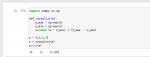
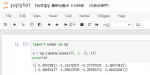
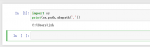
import numpy as np
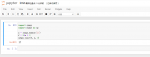
#将数组打乱随机排列 两种方法:
#1 np.random.shuffle(x):在原数组上进行,改变自身序列,无返回值。
x = np.arange(5)
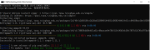
print(x)
np.random.shuffle(x)
print(x)
#2 np.random.permutation(x):不在原数组上进行,返回新的数组,不改变自身数组。
y = np.arange(5)
print(y)
z = np.random.